

In our last article, we looked at Retrieval Augmented Generation - a way to bring company’s data into the LLMs through the power of embeddings. In this article we expand on the latest research and advancements in prompt engineering and thought frameworks, to tackle an even broader range of use cases and applications.
CoT and ReAct
Chain-of-Thought (CoT) prompting is one of the techniques that showed striking improvements in performance on a range of arithmetic, commonsense and symbolic reasoning tasks with sufficiently large language models. In a few-shot setting, instead of standard prompting where a final answer is given directly, Chain-of-Thought proposes to teach the model how to perform a task by supplying reasoning steps in the exemplars. The model can then follow the same thought process to decompose an example never seen before into intermediate steps in order to provide the final response.
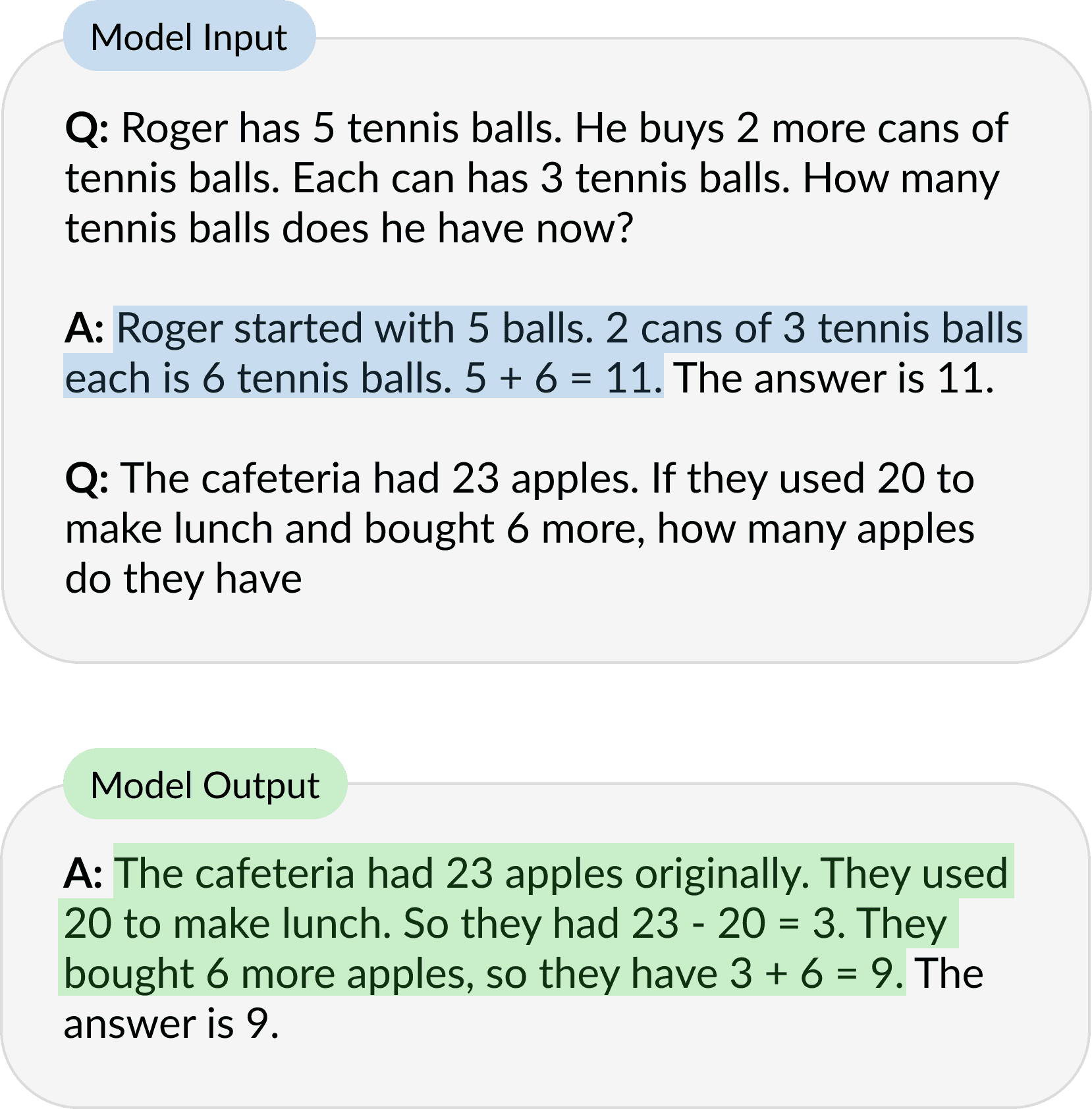
source: https://arxiv.org/abs/2201.11903
CoT prompting showed significant performance improvements with increasing model scale when tested using well-known arithmetic reasoning benchmarks such as MultiArtih and GSM8K and a range of smaller to larger language models, such as Google’s Language Model for Dialogue Applications (LaMDA) with 422 million to 137 billion parameters. In contrast, standard prompting performance did not improve substantially even for larger models. As these improvements get unlocked at sufficient model scale, they are referred to as emergent abilities.
One limitation of CoT prompting is the lack of interaction with an external world. Adding interactions brings valuable observations that the model can use to construct and execute a plan as it tries to solve multi-stage reasoning tasks. ReAct (Reason + Act) proposes such improvement by combining reasoning and acting stages, enabling the model to generate reasoning steps and text actions interchangeably. Depending on the nature of the task, the prompting technique can apply more emphasis on trace generation rather than action (reasoning) or actions (decision making). In either case, research has shown superior performance over standard, CoT or Act only prompting across several different benchmarks such as HotPotQA (question answering) or Fever (fact verification).
| HotpotQA (exact match, 6-shot) | FEVER (accuracy, 3-shot) | |
|---|---|---|
| Standard | 28.7 | 57.1 |
| Reason-only (CoT) | 29.4 | 56.3 |
| Act-only | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| Best ReAct + CoT Method | 35.1 | 64.6 |
| Supervised SoTA | 67.5 (using ~140k samples) | 89.5 (using ~90k samples) |
PaLM-540B prompting results on HotpotQA and Fever.
Agents
As research evolves so does the tooling that provides the building blocks for leveraging LLMs as a reasoning engine that involves interactions with an external world. The open source Langchain framework provides several ReAct style implementations tailored to use cases such as question answering or personal assistant. On the other hand, OpenAI Functions or AWS Agents in Amazon Bedrock are examples of fully managed agents that can easily tap into many powerful LLMs as well as integrate with a company’s private data stores and services.
Agents do not take predefined, isolated actions. Instead, they orchestrate an iterative process involving reasoning steps and interactions with APIs, Databases, Search Engines and other external sources that result in observations. These observations, in turn, serve as inputs for further actions and reasoning.
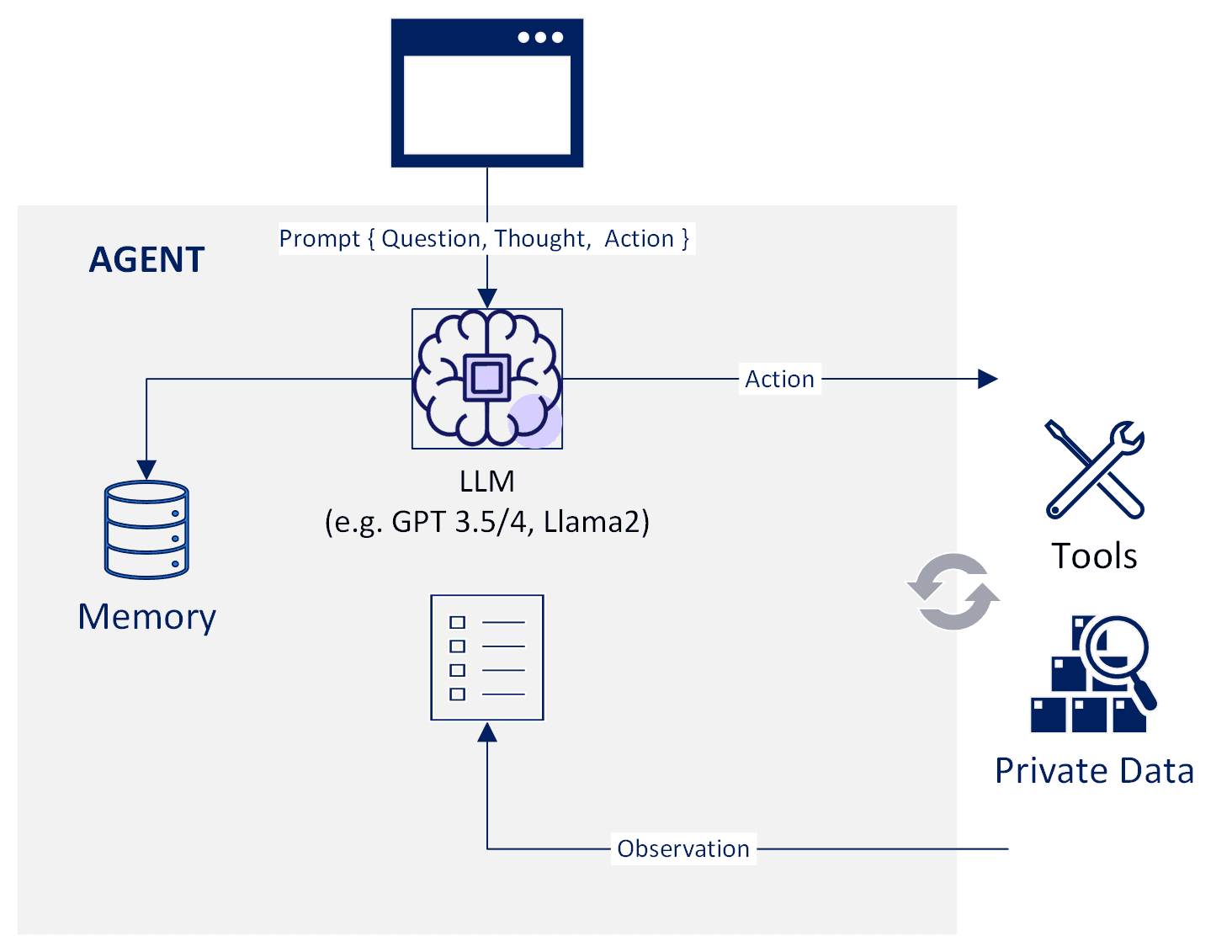
The capacity to learn from their actions and adapt based on observations makes them suitable to execute complex business tasks in a dynamic, fully automated way, including writing and executing code. Importantly, as agents determine and execute actions based on input and results of previous actions, they can recover from errors and take corrective steps.
A typical agent implementation involves designing a query using a prompt template, providing the tools, and defining the stopping condition. A stopping condition can be determined by the LLM or other factors such as the number of iterations or context length to avoid consuming too many resources. Output parsers can be used to extract observations and actionable insights in a structured way. In addition, agents can utilize memory stores or communicate with other agents.
The steps required to build agents can be reduced even further when using agent types provided by libraries such as Langchain. Below is an example that uses a general purpose ReAct style agent in conjunction with the yahoo finance tool providing up to date financial information.
import os
import yfinance as yf
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools.yahoo_finance_news import YahooFinanceNewsTool
llm = ChatOpenAI(temperature=0.0)
tools = [YahooFinanceNewsTool()]
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
agent_chain.run(
"Amazon just had a quarterly report, did it beat expectations?",
)With a few lines of code, the agent is now ready to utilize the provided tools and the power of the LLM’s reasoning. Since we have specified verbose output, we can see the reasoning stages that led to actions that produced observations, and how the model arrived at its conclusion.

Agents can just as easily utilize multiple tools. For example, this basic example could be extended to search Google or X for latest commentary and measure sentiment using LLM. When running in the cloud, it could securely integrate with a database or vector store for insights or metrics derived from private data.
Agents can utilize memory for Agent to Tool or Agent to LLM interactions. In its simplest form, memory helps provide sufficient context back to the LLM and can reduce the number of calls required. Advanced agent implementations such as AutoGPT and BabyAGI, that have become well known for their ability to tackle open-ended objectives that demand numerous actions and complex execution plans, have utilized long term memory in the form of vector databases to help the agent store and prioritize tasks effectively.
Conclusion
As we are still early in exploring and understanding the potential of rapidly evolving Language Models and Tools, AI agents show incredible potential in addressing complex business use cases and applications. Thanks to research from prominent institutions and companies focused on understanding reasoning traces and thought patterns, emergent abilities are being discovered in LLMs leading to new innovative ways of extracting value from AI powered solutions. Already we’re seeing multiple agents or multimodal prompting extending the roam of possibilities. The journey is just beginning, and the versatility and potential of agents is far from being fully realized.



