

Retrieval Augmented Generation (RAG) is a way to enhance prompts with up-to-date information from one or more external sources of knowledge. Today, organizations store data in cloud storage solutions, databases, or APIs. RAG combines the power of foundational models with the efficiency of retrieval-based systems, offering a dynamic and adaptable approach to handling domain specific queries. It also proves to be an effective mechanism for constraining (grounding) the model in trusted content, leaving an organization with better understanding and control over the sources of truth the response was formulated on. Furthermore, RAG offers a way around context length limitation present in many of today’s LMs where the input to the generative model can be much shorter due to the condensed response provided by the retriever. This provides the ability to process long documents or carry out tasks that require extensive context comprehension.
RAG flow
At a high level, RAG can be broken down into three phases - Data Ingestion, Retrieval and Query.
In the initial stage, documents are converted into vector representations using an embedding model. Vector embeddings are numerical representations of objects such as words, sentences, documents, or other modalities such as images, audio, or video. These numerical representations encapsulate the meaning and relationships in a multidimensional vector space, clustering similar data points closer together. This makes them suitable for many machine learning tasks such as semantic similarity, recommendation systems, anomaly detection, image captioning and more.
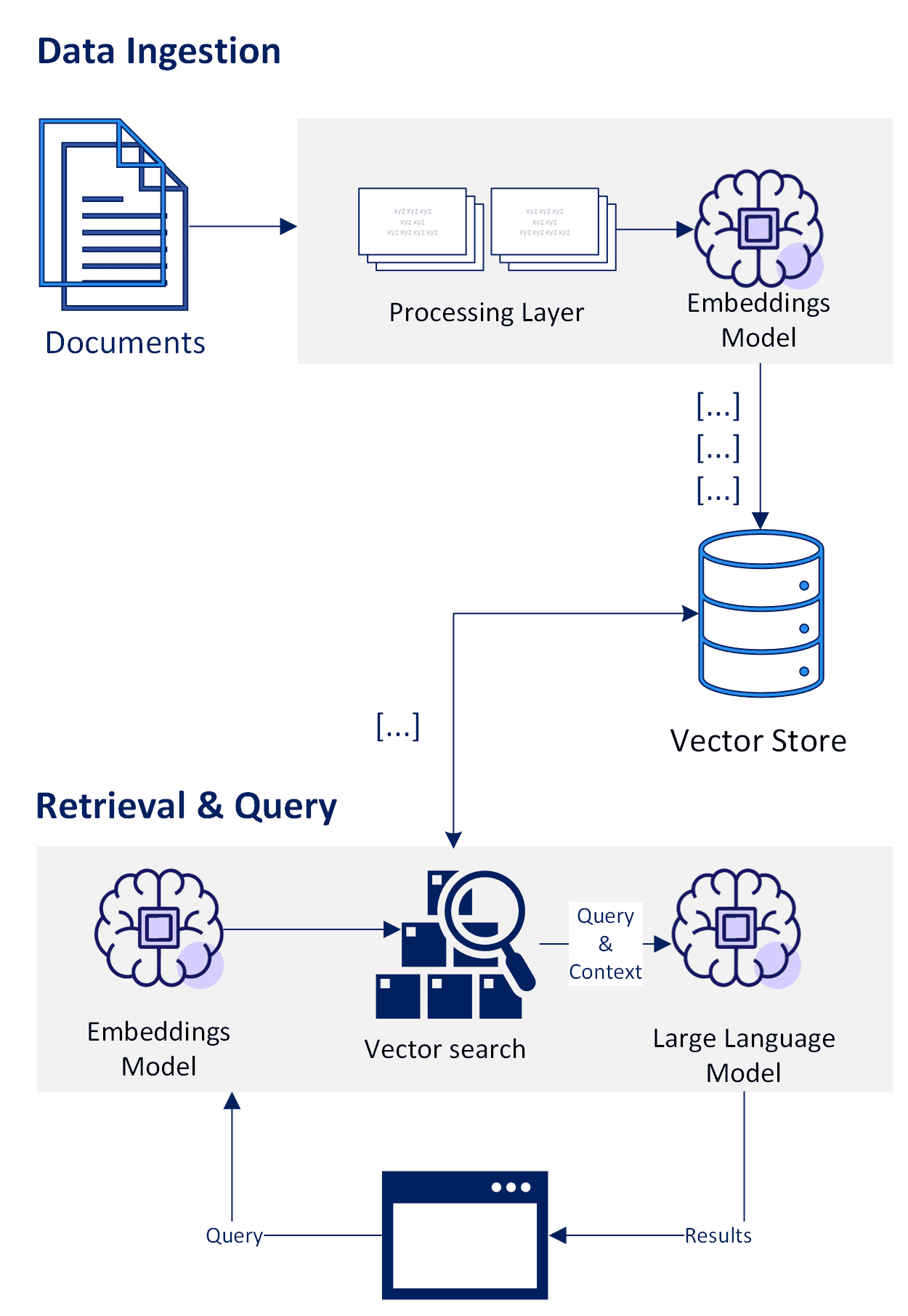
While organizations store data in structured and unstructured form, extracting and preparing unstructured data becomes increasingly more critical due to the rapidly increasing volumes and the potential value offered to machine learning tasks. Recent projections estimate 80% of enterprise data will be unstructured by 2025. While file formats such as html, pdf, office, markdown, etc... have become a standard way of organizing and sharing knowledge within an organization, the need for innovative tools and pipelines to harness the wealth of information effectively increased.
The preprocessing stage following extraction typically involves a series of steps such as cleaning, curation, transformation, and chunking. A proper chunking algorithm must be evaluated to ensure continuity of context and many powerful libraries exist to aid in this task. The Nature Language Toolkit (NLTK), Spacy, Langchain’s Character Text Splitter rely predominantly on linguistic rules, while more advanced options utilize semantic similarity through sentence clustering.
Next, document chunks are turned into embeddings using an embedding model and indexed in a vector store. Vector databases index and search objects using an approximate nearest neighbor algorithm. An embedding model can be selected from a variety of specialized, open source or hosted models such as Open AI or Cohere embedding APIs. More common vector databases include open-source options such as Chroma, pgvector, Faiss, Weaviate, OpenSearch to fully managed, proprietary hosted solutions such as Pinecone. Faiss or Chroma are often great for experiments and early evaluation as they can be self-hosted without requiring significant resources while hosted solutions such as Pinecone offer auto scale without requiring cloud infrastructure expertise.
With document chunks in vector store, we can search for the most relevant documents to the provided query. Under the covers, the vector store will try to find the closest distance between the query and the vectors indexed in the database, utilizing one or more algorithms such as Cosine Similarity or k-Nearest Neighbors (k-NN). This can be abstracted away into a higher level api such as the one presented below that uses LangChain along with Faiss to perform a similarity search and return results with scores.
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import PyPDFLoader
# load pdf document
loader = PyPDFLoader("transcript.pdf")
content = loader.load()
# create chunks and embeddings
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(content)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
# run similarity search
query = “”
results = db.similarity_search_with_score(query)Scores are providing a measure of relevancy based on the distance between the vectors.
The most relevant documents found are included in the prompt to provide additional context next to the query. Here again, LangChain provides utility functions for quickly constructing a prompt this way and passing into the model.
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAIchain = RetrievalQAWithSourcesChain.from_chain_type(OpenAI(temperature=0),
chain_type="stuff", retriever=db.as_retriever())
result = qa_chain({"query": question})Conclusion
Retrieval Augmented Generation is a significant step in broadening the adoption of LMs in business use cases. While proper prompt engineering is a critical part of a well-functioning, AI aided solution, rapid progress in libraries and tools including managed services and vector databases significantly lowers the cost and level of effort required to implement.
With the ability to ground responses in trusted sources of information, RAG ensures that the knowledge it draws upon is both reliable and accurate. Furthermore, it proves to be an effective mechanism around context length limitation as well as a straightforward way to control and update language model’s output. By supplying context from a broader source, the model can better understand the nuances of a topic, access relevant historical information, and make more informed decisions. Last but not least, it promises to be an effective way to extend the capabilities of language models to incorporate multiple modalities, such as images, audio, or video, the direction data and information is inevitably moving towards.



