

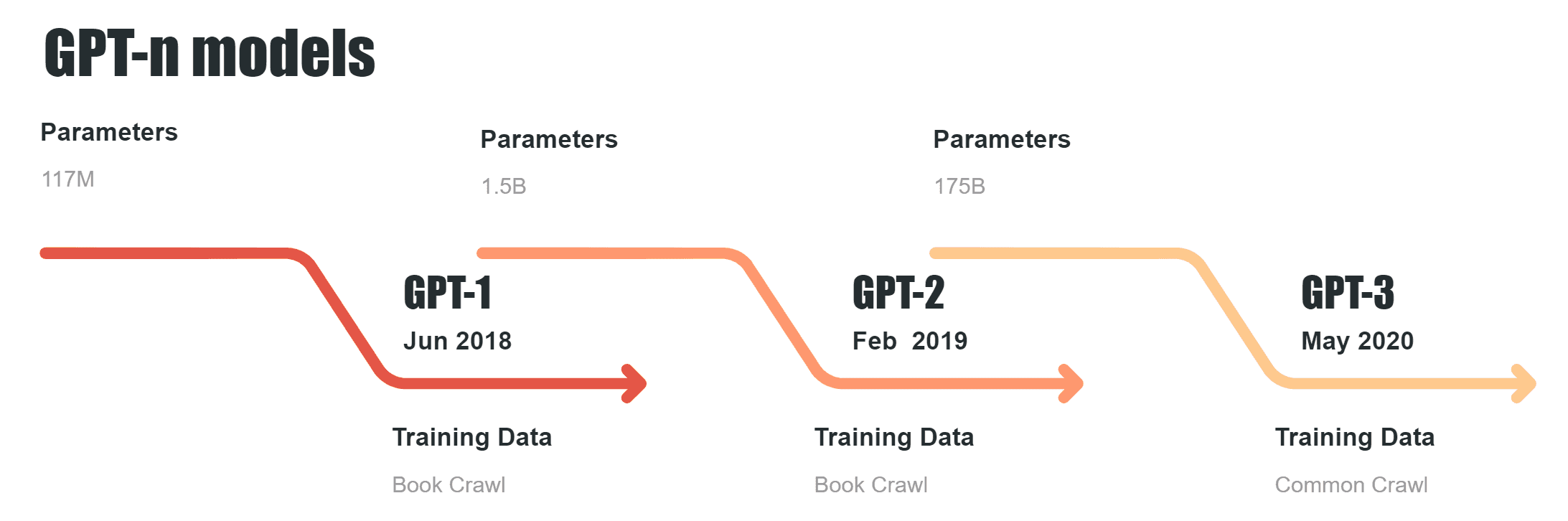
GPT-1 has 117 million parameters and was trained using the BooksCorpus dataset, which consists of around seven thousand unpublished books.
GPT-2 has 1.5 billion parameters and was trained using a new corpus, created by OpenAI, known as WebText. This consisted of around 8 million web pages and was generated from links on reddit with at least three upvotes. The results were then cleaned, duplicates eliminated, wikipedia pages eliminated (due to their occurrence in other datasets) and then the remaining pages parsed into plain text. GPT-3 has 175 billion parameters and approximately 45TB of text data from the following sources:
|
Dataset |
Quantity (tokens) |
Weight in training mix |
Epochs elapsed when training for 300B tokens |
|---|---|---|---|
|
Common Crawl (filtered) |
410 billion |
60% |
0.44 |
|
WebText2 |
19 billion |
22% |
2.9 |
|
Books1 |
12 billion |
8% |
1.9 |
|
Books2 |
55 billion |
8% |
0.43 |
|
Wikipedia |
3 billion |
3% |
3.4 |
Sizes, architectures, and learning hyper-parameters (batch size in tokens and learning rate) of the models which we trained. All models were trained for a total of 300 billion tokens.
The leap in ability from GPT-1 to GPT-2 was spectacular, as the data set it was trained on was considerably larger than had been previously available. As a result, answers were more human-like than before. Fine tuning was required of the GPT-2 model, as some of its output was considered “unsafe”. Fine tuning was carried out with human feedback for various tasks to improve the output.
The latest model, GPT-3, was released in 2020 and is currently the most advanced language model openly available. It has 175 billion parameters allowing it the ability to generate high quality text at times indistinguishable from human output.
In January 2022, Open AI released their fine tuned version of GPT-3, InstructGPT. OpenAI said that the model was “much better at following user intention than GPT-3, while also making them more truthful and less toxic”. The models were trained with humans as an integral part of the loop. Their aim was to align language models with user intent. This was achieved through fine tuning with human feedback on a much greater scale than was attempted with GPT-2.
More recently, in November 2022, OpenAI released ChatGPT, as a sibling model to InstructGPT. The chat format was designed to make it possible to answer follow up questions, reject inappropriate requests and challenge false premises. The model was fine tuned using RLHF (Reinforcement Learning from Human Feedback) and is currently being further fine tuned by gathering user response data on their site https://chat.openai.com/chat They will use the feedback to help inform the next evolution of their system.
GPT-3 demonstrates substantial gains in task-agnostic, few-shot settings (described next) compared to prior models that were able to achieve similar performance with specific fine-tuning techniques applied.
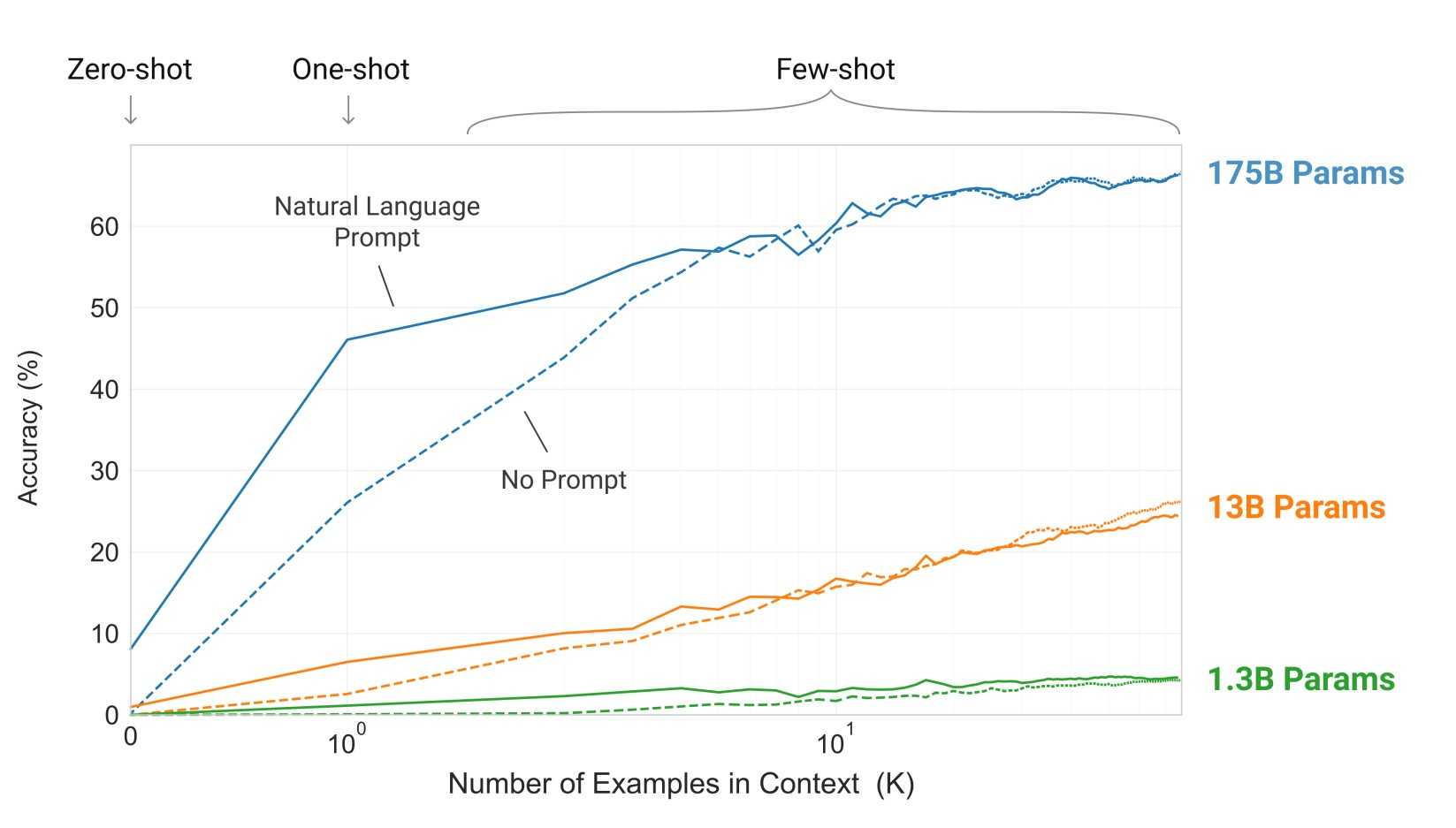
Zero shot learning allows the model to perform a task correctly without having to provide a labeled dataset, resembling the ability of a human being to perform tasks based on natural language instructions and prior knowledge acquired.
An example of a zero-shot might be image captioning where the model will generate a text caption without having been pre-trained on image/caption examples. In a one-shot setting, the model receives one example of the task in addition to the initial instruction. The one shot model is used in facial recognition tasks. The model will have one example of a face, but is expected to be able to recognise it with different lighting, hair style, expression etc. Finally in a few-shot setting, multiple examples of the task is enough for a high level of accuracy. An example might be online retainers and advertisers predictively modeling suitable products for future purchases based on past purchase behavior.
With GPT-3 the Open AI research team as well as the broader community also discovered that designing a prompt correctly plays an important role in how well the model performs. Aiding the model with subtle cues or additional words can change the outcome of a task leading to many publications and videos online on improving the quality of the results.
While there is a substantial gain in terms of performance, there are still plenty of situations where the model doesn’t perform with an acceptable level of accuracy. For example, the accuracy results of tasks designed around natural language inference showed much less progress compared to other tasks. The model continues to evolve and we can expect the gap to narrow with every future release.
Open AI provides several models designed for different form factors and with different price levels. The more prominent models available are Ada, Babbage, Curie and Davinci.
Each of these different models process the same request with differing speed, output and cost. This is so that the user is able to select the most appropriate tool for the task. The following image from https://openai.com/api/pricing/ shows the price differential between the three models.
Each model will provide different outputs to the same query. For example, the query “Write a promotional article for a computer shop” generates the following:
Ada provides a simple, rapid response to the query -

Babbage has created a more generic article and has taken the request for “a computer shop” quite literally -

Curie has understood that it is a specific shop it must write about and has created a more engaging article -
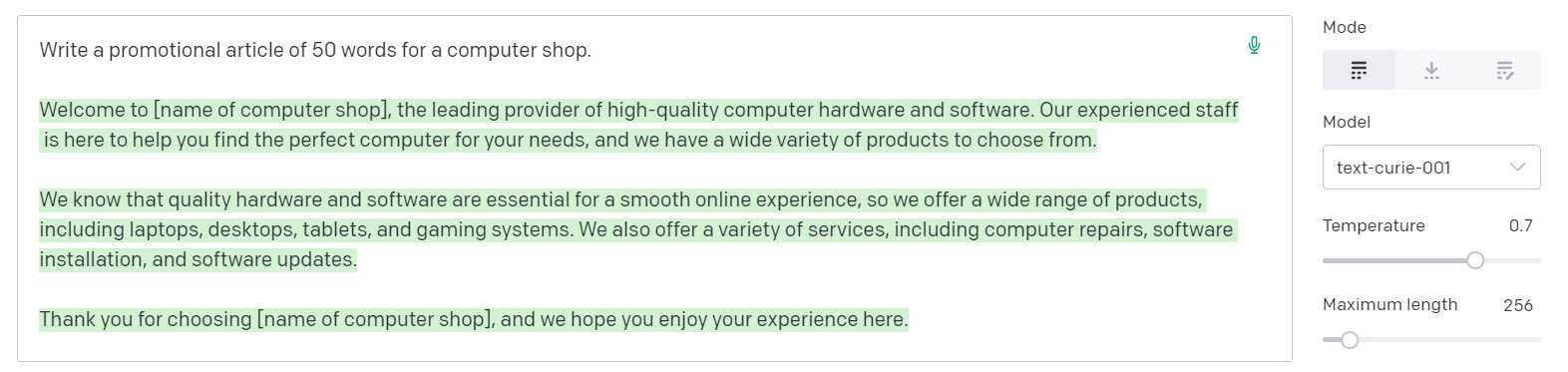
Finally, Davinci has created an article using enticing language, ideally suited to the task at hand -

Although this is a simple example, it demonstrates varying capabilities in each model. Creativity may not be as important as price when asking the AI to analyze vast swathes of data, so the cheaper options of Ada/Babbage may be selected. Whereas if the AI is being used to generate prose, engage in chat or other more complicated tasks with greater human interaction, it is perhaps more appropriate to select Curie or Davinci.
Bias, fairness and safety
The Open AI team published several metrics indicating the model could be biased towards a particular gender, race or religion. This is why both Open AI as well as other vendors providing access to the API, such as Microsoft Azure, have worked on providing content filters for detecting harmful or inappropriate prompts or responses. The Moderation API provided by Open AI or tools available inside of Microsoft Azure are being developed as safety net around this powerful capability.
Use cases
While Natural Language Processing has made significant contributions across a wide range of industries and disciplines, Natural Language Generation has provided an extra gear over the past few years, redefining problem spaces, accelerating innovation and creating a new generation of applications.
Content Generation
From copywriting, articles, books, prose and poetry, through legal contracts, presentations, invoices, to software or games, language generators are finding a permanent place in the toolbox of creators and professionals. Jasper.ai is a highly popular AI-powered content generation service known for high-quality and engaging content. Github’s code pilot is enhancing productivity of programmers across many programming languages. Other form factors are emerging such as images with DALL-E or Midjourney.
Document Review
Generating summaries, translation, sentiment analysis, pattern recognition, fraud detection, compliance checking makes GPT-3 a great aid in many time consuming and costly tasks professional are undertaking every day.
Customer Support
Chat GPT has proved capable of responding to customer inquires. Its ability to preserve context throughout a conversation means that questions or complaints can be refined and narrowed down, improving customer service response time and accuracy.
Entertainment
Games such as AI Dungeon, generated entirely from a few prompts, give the designers and players the ability to create and customize the experience much faster and easier than ever before.
Virtual Assistants
Bots capable of performing many mundane, repetitive tasks are bringing productivity into businesses, customers and end users in a conversational form factor everyone feels familiar and comfortable with.
Conclusion
Undoubtedly the emergence of Open AI services and its GPT-3 language model puts a lot of old problems in a new light, amplifying the human mind, creating conversations and ideas that have the potential to reimagine, transform or disrupt how businesses and customers interact with technology. From startups built from a ground up on top of this powerful technology to market leaders the likes of Google putting their executives on alert, businesses are adapting to this new reality before their competitors will.
References:
- Language Models are Few-Shot Learners on arxiv.org
- A New Chat Bot Is a ‘Code Red’ for Google’s Search Business on New Yourk Times


